
Why Do You Need Vector Processing to Win in the AI Era?

In today’s data economy, there are many markets to buy, sell, and exchange data. Companies like Kaggle or Refinitiv monetize data as the basis of their business model. Others augment existing products by selling their data – industrial equipment providers like Siemens sell products with advanced data collected from devices – or by building industry data utilities to monitor equipment or networks precisely. Still others make open source data available to engage the developer ecosystem: think of President Obama’s 2010 Open Data Initiative that sparked the community to share data for public transportation and other public works.
Yet the typical shortfall in these datasets is that they only represent static snapshots in time. As a customer, you essentially get access to one “exposure” of data that is often outdated and one-dimensional, so it’s far less valuable. It can’t be leveraged in ways that command a premium price.
To keep their data fresh, many companies download a day’s worth of the data they need, upload it to a database, then run the same pattern 24 hours later in an endless loop. The new data replaces the old data, and rather than becoming a monetizable source of value, the company creates a single out-of-date view with a set of backups.
More connected organizations, like trading firms, use live connections and “feed handlers” to connect to real-time data streams. These streaming data feeds provide a more nuanced, temporal point of view of data. This kind of data management is like watching a movie, not just staring at a single frame.
A technology up to the data task
Since companies that sell historical and real-time insight can’t run on yesterday’s news, many are looking for a solution that enables their customers to subscribe and build applications against premium, dynamic, time-based data. This allows data users to roll back the clock dynamically, rewatch a series of sensor readings in the exact order that led up to an equipment failure, or, in the case of financial markets, design algorithms based on temporal patterns that lead to trading opportunities.
This time-based data helps consumers “rewind the tape” and replay why, when, and what led up to a specific business event. This is a far more exciting opportunity than using data that’s outdated by the time it’s uploaded and that runs the risk of missing significant events.

Another obstacle to leveraging static data is that snapshots are often delivered in their raw state. It must be filtered, cleansed, aggregated, and normalized, then have business rules applied before it’s ready for use in an application such as AI. Consider the significant value-add that a company could build into a service offering if they could deliver data that is optimized on the fly for use before their customers receive it.
Data replay is essential for automation and AI explainability
The ability to “play back the tape” of data is essential to manage automated systems effectively. A temporal view of data helps you understand how an automated system behaves, how to optimize the algorithms that make automated decisions, and, when things go wrong, to replay events for forensic understanding.

The ability to understand the temporal nature of data is also critical with AI because of explainability. Generative AI applications, for example, exhibit so-called emergent behavior – they create new, different, and surprising output as their data corpus expands over time.
Access to temporal data helps understand why an AI model chose or recommended a decision the way it did. If your data is organized by time, you can replay and analyze your model’s worldview at the precise historical moment it made that recommendation. You can also confidently cross-reference any data used for predictive purposes versus relying on anecdotes or your memory.
Without temporal explainability, users may trust but can’t verify the results produced by a generative AI model. Lack of explainability is precisely why many regulatory and legal organizations – not to mention large technology companies – have declared AI-generated data used in risk modeling, reconciliation, and real-time transaction management to be inadmissible or to require human review – and why predictive analytics models are far from gold-standard status in most industries.
The one-two punch: time-series data + vector processing
Of course, analyzing billions or trillions of time-series data points in an AI application sounds daunting at best. There needs to be more than time-series data to meet the demands of our real-time world. And conducting multidimensional similarity search or predictive analytics is a big headache in traditional databases such as SQL, which store and manipulate information in rows, while time-series data is inherently ordered by column.
Enter the vector database. Along with time-series data, vector processing – and its ready applicability as a storage mechanism for so-called vector embeddings – is the crucial second ingredient of a winning data economy platform.
How does vector processing work? First, storing data as vectors is as simple as storing interrelated data elements as vectors. That notion is familiar to any user of technical computing tooling, like Python, MATLAB, R, or Julia. A vector takes on a particular meaning within generative AI, commonly called vector embeddings. Here, it indexes and stores data – especially unstructured data such as images, video, audio, or social media– as numerical values based on similarities. This dramatically simplifies retrieving data and finding similarities or meaningful anomalies in it.
Vectors have always facilitated new levels of speed in the data management and data analytics equation: indexing vector-embedded numbers and processing them as stored vectors rather than rows increases query speeds. And since time is also both a vector and a characteristic of any data object, it makes sense to store and query time-series data in vector databases, i.e., those designed to handle all vector types, not just those geared to vector embeddings. In an AI setting, you get the best of both worlds – blazing speed and complete command of data based on when it was recorded. Not to mention the ability to incorporate the new language of generative AI.
Anyone looking into this space will encounter vendors offering plain vanilla vector databases, which means those running generative AI applications through vector embeddings. However, those vendors miss the bigger time-series picture, vector processing with vectors managing time-based information – which drives the predictive analytics commonly conducted in statistics and signal processing. In short, why limit yourself to generative AI when you can also reap the benefits of processing time-series data?
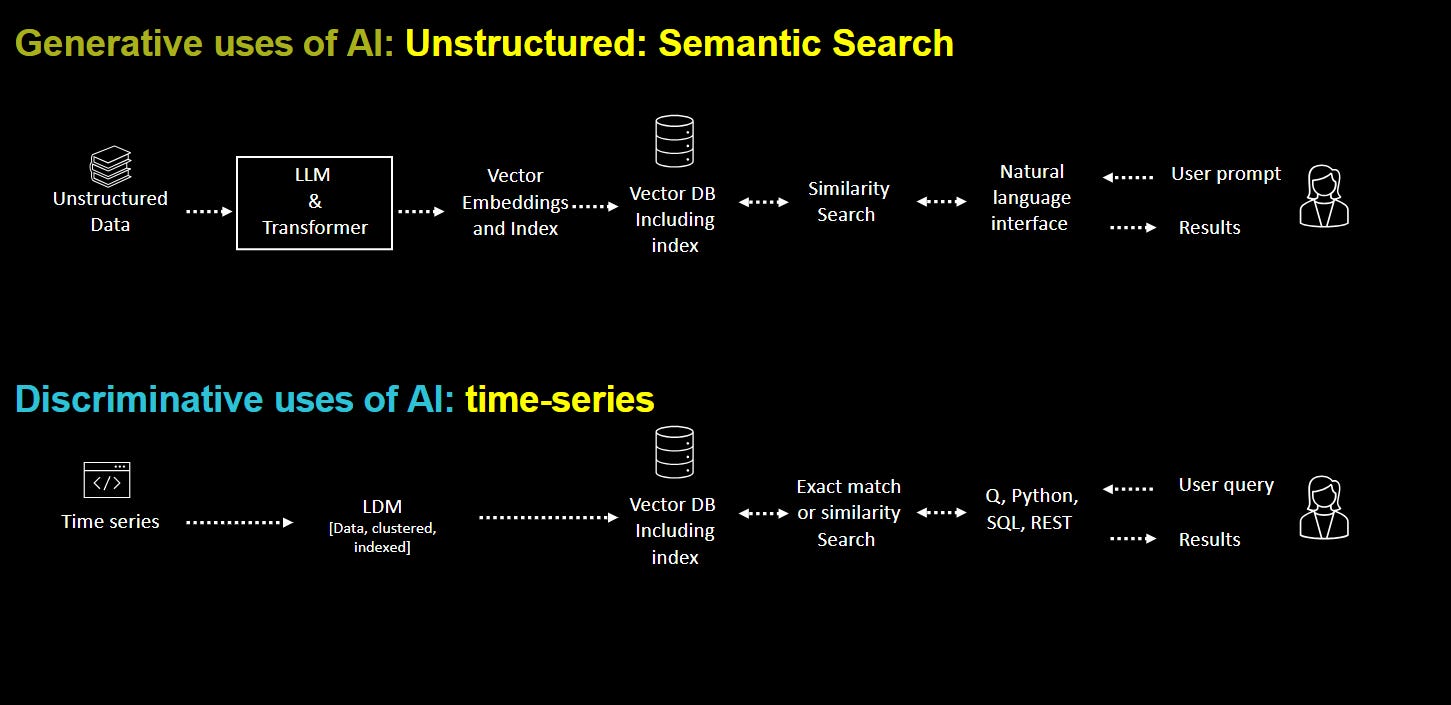
The ability to perform vector processing on time-series data enables applications to search any data type based on its timestamp. Exact results can be reviewed instantly for compliance and explainability purposes. At the same time, predictive analytics become far more potent by accessing historical and temporal views of business events.
Marrying analytic sophistication to speed
An excellent example of using time-series data and vector processing to create an advantage is the contract research organization Syneos. Syneos is using vector processing for its time-series trials data – such as patients’ vital statistics, lab test results, adverse events, and disease-specific measures – to answer complex questions in a fraction of a second, or what the company’s head of data science calls “at the speed of thought.”

Combining time-series and vector data approaches allows Syneos to pose and answer questions such as:
When was the last outbreak of this new virus, and in which precise locations?
Which trials ran in two countries, and how did they perform?
What symptoms do people have in this trial, and can we correlate them with symptoms they had in other trials, which were seemingly unrelated?
This power allows Syneos to cut time and effort from clinical trials, which typically run at $1 million daily.
The ultimate goal: accurate, real-time awareness
Where else will vector processing and time-aware automation create business impact?
Consider customer service. Imagine the competitive advantage of addressing every customer’s needs because your reps have the full context of each issue (and the full history) with your service at their fingertips. The infusion of temporal analytics and quantitatively backed data and predictions in the generative AI space is made possible with vector-native, time-series data technology.
Imagine being able to rewind the tape on suspicious patterns of sensor readings from industrial equipment and more easily predict and fix failures before they happen.
Or imagine being able to perform forensics on any business condition to understand better what went wrong or right.
These applications are just the beginning. Organizations from smart cities and utilities to manufacturing, banking, and telecommunications will increasingly thrive or fail based on the quality and timeliness of their data. Working with vendors that offer a unique combination of time-series and vector database technology is the fastest and most computationally efficient way to drive innovation and remain resilient in today’s data economy.