
Five Ways Vector Databases Are Created Equal (and Not)
Vector databases are hot, but they aren't all created equal. Here are five ways they're similar and five ways they're vitally different.

Are all vector databases the same?
Are all automobiles the same?
Our cars all have the same functional purpose – to move us from one place to another. They all have a similar foundation, a chassis. But there are seemingly infinite ways in which each car model differs from others, even within their class, in terms of power, utility, style, and features.
In addition, for more than 100 years, automobile manufacturers have developed new technologies that meet new user needs. From the Model T to muscle cars to minivans to EVs, humans keep reinventing cars as our requirements evolve.
Similarly, all databases are the same on a functional level. They’re all designed to manage your data safely and let you query it quickly. But just as EVs have fundamental differences from gas-powered cars – and no EV model is identical to any other EV – not all vector databases are alike within this new technology class.

Here’s a process for identifying the best vector database for you.
How most vector databases are the same
Vector databases are uniquely suited for generative AI applications based on their unique ability to encode images, audio, space, time, and other unstructured data using vector embedding. This means that they convert complex data types into a list of numbers that a machine-learning model can use to run similarity searches and other operations.
They also store data in columns rather than rows, making it easier to plot objects via their dimensions (height, width, price, leading actor, sensor temperature, device pressure, etc.). They are highly efficient at processing enormous data volumes. You could think of vector databases as high-performance sports cars.
Also, most vector databases are designed to do “database things,” including:
Store data in large quantities. This can extend into multiple terabytes
Support hundreds (or even billions) of dimensions for each piece of data. As many ways as you can categorize something, it’s the job of a database to be highly scalable to handle the volumes of data you have
Create indexes for lightning-fast querying. All databases are designed to answer questions quickly, according to their underlying data types. Vector databases are uniquely designed to answer questions about data
Use distributed architectures and parallel processing. This provides scale, performance, and flexibility for how the database is managed, including its large datasets
Allow for flexible queries. This includes filtering, aggregations, and investigations that combine vector similarity and other relational operations

The canonical illustration below shows the “least common denominator” use of vector databases: static, unstructured data flows in on the left, that data is transformed into vector embeddings and database indexes, and end users submit similarity or anomaly queries with SQL or natural language. This is a classic example of generative AI of the type you see in ChatGPT and similar models.
How some vector databases are different
On the other hand, not all vector databases are alike. First, like all high-performance cars, every vector database performs the five tasks above quite differently. For example, not all vector databases run at the same speed. You can easily find benchmarks that compare them, although we won’t do that here.
Also, some vector databases are designed for static data that doesn’t change -- others are optimized for streaming data like sensor reading from IoT devices or market data in the capital markets.
There are several areas where vector databases are wildly divergent.
All-purpose versus specific use case. Some vector databases, like an SUV, are designed for multiple-use models, while others are optimized for particular use cases, like IoT.
Static versus dynamic data. Some vector databases are optimized for similarity and anomaly search on relatively static data, loaded once or twice a day, weekly, or daily. Others are designed for constantly changing data, like online transactions from digital applications, log file updates, and of course, IoT sensor readings. This is streaming data; not all vector databases are optimized to handle it.
Query-response versus push-based interaction model. Databases designed for constantly changing operational data have features that allow them to “hold” questions from end users and continuously evaluate them. They couple this query processing style with the ability to push results to end-users rather than requiring that users repeatedly “ask” the database for new results. This is called push-based query processing; not all vector databases support it.
Toolkit versus turnkey. Some vector databases are designed as “toolkits” – open-source APIs and code-first interfaces. These are like kit cars – you have to build them yourself. Some vector databases are designed for you to jump in and drive them off the lot into your AI and ML ecosystem, with pre-packaged interfaces to the other tools you use.
For example, some vector databases come pre-configured to absorb data from popular hyperscaler tools on AWS, Azure, or Google Cloud. Some have pre-configured integration with Anaconda, Python, or common DSML platforms. This is akin to how cars differ in their fit, finish, style, and convenience factors.
Open source vector databases versus proprietary. Some vector databases are built in open-source languages or have an open-source front end, while others require you to know a proprietary language. Again, this isn’t true of all vector databases, but it certainly broadens their potential popularity if they are accessible in a language like Python.
Although some database technologists don’t always consider these factors first, they’re essential to others in choosing the best vector database for their needs. This includes business analysts, business intelligence tool users, and data scientists that need fast, user-friendly access to data from the tools of their choice.
Horses for courses: why different styles of vector database match different use cases
Some families need an SUV. Others care more about style or speed. Still, others care mostly about the engine's efficiency inside, from fuel-efficient gas combustion engines to the most sophisticated EV technology.
The same holds for vector databases. Here are a few “styles” of data processing that necessitate different approaches to vectors.
Raw in-memory speed and query performance
Sometimes the most essential requirement of your application is to go from zero to 60 as quickly as possible. For these applications, look for a vector database optimized for in-memory computation. For example, some query processors are designed to carefully use GPUs to provide lightning-fast query responses or, in the case of streamlined data, absorb 50,000 data updates a second.
When you need speed, test your database on the road.
Time-series data
Nearly all data from IoT sensors, machine readings, medical tests, and other sources is time-stamped. Organizing data by time allows any company to pick a point in their data store’s history and recreate it with a 360-degree view of what conditions looked like, then step through event by event – what happened, in what order, and why.
The graphic below shows an example of time-series, discriminative AI: an AI model focusing on clustered, indexed data and where the boundaries between data types lie versus how the data is embedded in space. These models are often chosen for sentiment analysis, natural language processing, and recommendation systems.

Time-ordered data allows you to gather regulatory evidence for preventative enforcement, recreate the “crime scene” of nefarious financial market activity, and provide a complete overview of all technology telemetry – all data from remote sensors – from a central location, then analyze it to monitor and control remote devices in areas such latency.
LLM and LDM support
Large language models are typically formed around unstructured data assets, while large data models tend to be built on heavily structured data formats such as sequential data (stock prices, weather measurements, sensor readings) in high volume.
If your vector database can support both, you’ll get highly accurate results based on time and highly contextual based on rich details such as location, cultural norms, relationships, and so on.
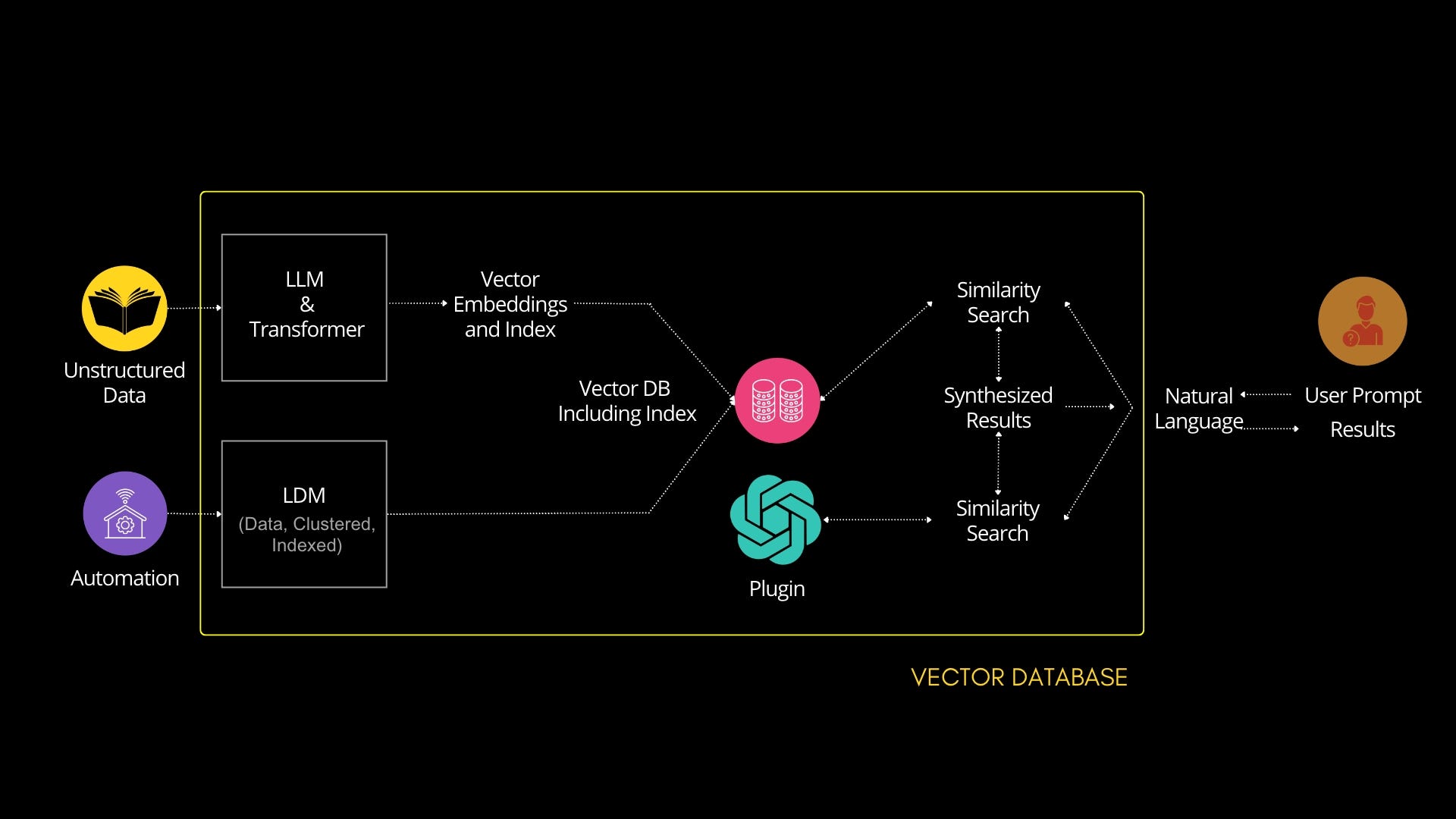
When a vector database supports both types of data – unstructured and time series, the database architecture expands, as do the quality and reliability of the results and the possibilities for your business.
Scaling with or without GPUs
Like cars, which use either fossil fuels or battery power, how a vector database achieves its performance matters.
Graphic Processing Units, which manipulate and alter memory to speed the creation of images for a display device, are heavily deployed in most vector databases.
However, they may not need GPUs when vectorized programming – and storage – accompanies some vector databases. This is very much a consideration today based on the increasing cost of computing and dependence on the availability of GPU chips.
Where it runs: cloud, on-premise, or both
You can’t drive just any car on the beach!
Some vector databases are only available in the cloud. Despite the excitement and ubiquity of the cloud, most of the world’s database capacity is still inside the “four walls” of most companies.
Some vector databases are designed to run anywhere: in the cloud, as a SaaS offering, or on-premise, wherever you need them. On-premise use is key when accessing secure, proprietary, and private datasets or even in private clouds like the U.S. government’s FedRAMP security framework.
Discriminative + generative
Combine the ability to support generative and discriminative uses of AI, and you open up the possibility for genuinely differentiating applications – what BCG calls “golden use cases,” those that “bring true competitive advantage and create the largest impact relative to existing, best-in-class solutions” – in fraud detection, recommendation engines, and predictive analytics, for example. You are also able to use one vector database to support dynamic pricing, demand forecasting, ad spend optimization, algorithmic trading (discriminative uses) as well as writing tasks, customer chatbots, new material synthesis, and design drafts.
The big, wide world of vector databases
Like the cars we drive, not all vector databases are the same. From simple query-and-response applications with static information to high-speed, high-throughput automated environments with IoT, one size does not fit all.
Only vector-native, time-series database technology equips the enterprise to deliver the full value of AI and automation and do it faster than traditional databases. If this is your goal, use this guide to think about how to enter the wonderful world of vector databases!